Job Fiction
How to find a perfect data science job?
Job titles for data science jobs vary from the obvious “Data Scientist” to the
vague “BI Analyst”. The term analyst may mean analyzing large data sets, or
analyzing a call center request.
"Job Fiction" helps you find best jobs matching your dream job description
and your preferences, not just the job title or keywords.
How to find a perfect data science job?
There are many websites out there to assist a job seeker to find jobs they may be interested in. They typically come in two flavors, or a combination of these:
- Search for jobs via keywords the job seeker enters
- Search for jobs via the job seeker’s resume
The problem with A is, it requires to know the exact words to search for. Our experience is, if you search for
- “Data Scientist” - Typically shows jobs with doctorate degrees or managing data science teams
- “Data Analyst” - May result in jobs for insurance auditors or business intelligence related.
- “Data” - Will turn up data entry clerk positions. That is a lot of irrelevant job postings to filter through.
B on the other hand is useful if you have related experience and are looking for lateral move. However, if you are looking for a career change, it may not give job matches in your target field.
Our project "Job Fiction" addresses this challenge in an innovative way. Click to learn more.
Our Solution in 3 Steps
1. Create Fictional Job
Start with a job description that you like; something you think sound like a good fit for you. Infact, why not start with 3 good sounding jobs and create a model that takes the best features of each of these to create a fictional job model.
2. Set preferences
Since no job is ever perfect, adjust the job model to highlight the job features important to you, and deemphasize what you do not want.
3. Get Recommendations
Now, with this model of the fictional perfect job – the combination of job descriptions and priority features, lets find job postings that are great matches for you.
Approach
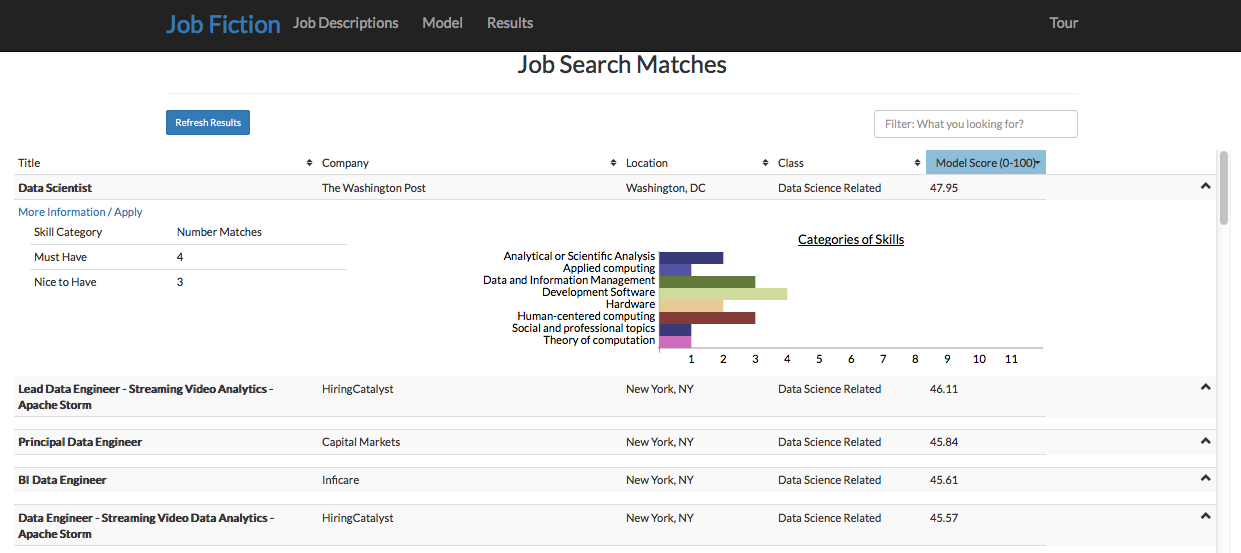
The key differentiator in our approach is finding job recommendations based on the job description and not just keywords or job title. Our approach can assure job results align with job seeker's interests regardless of the job titles.
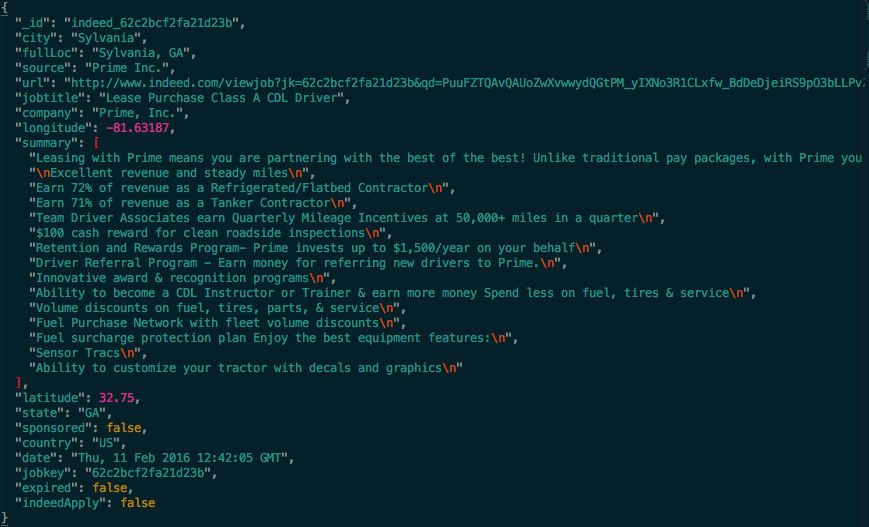
Data collection, acquisition and storage
Data analysis, discoveries and insights
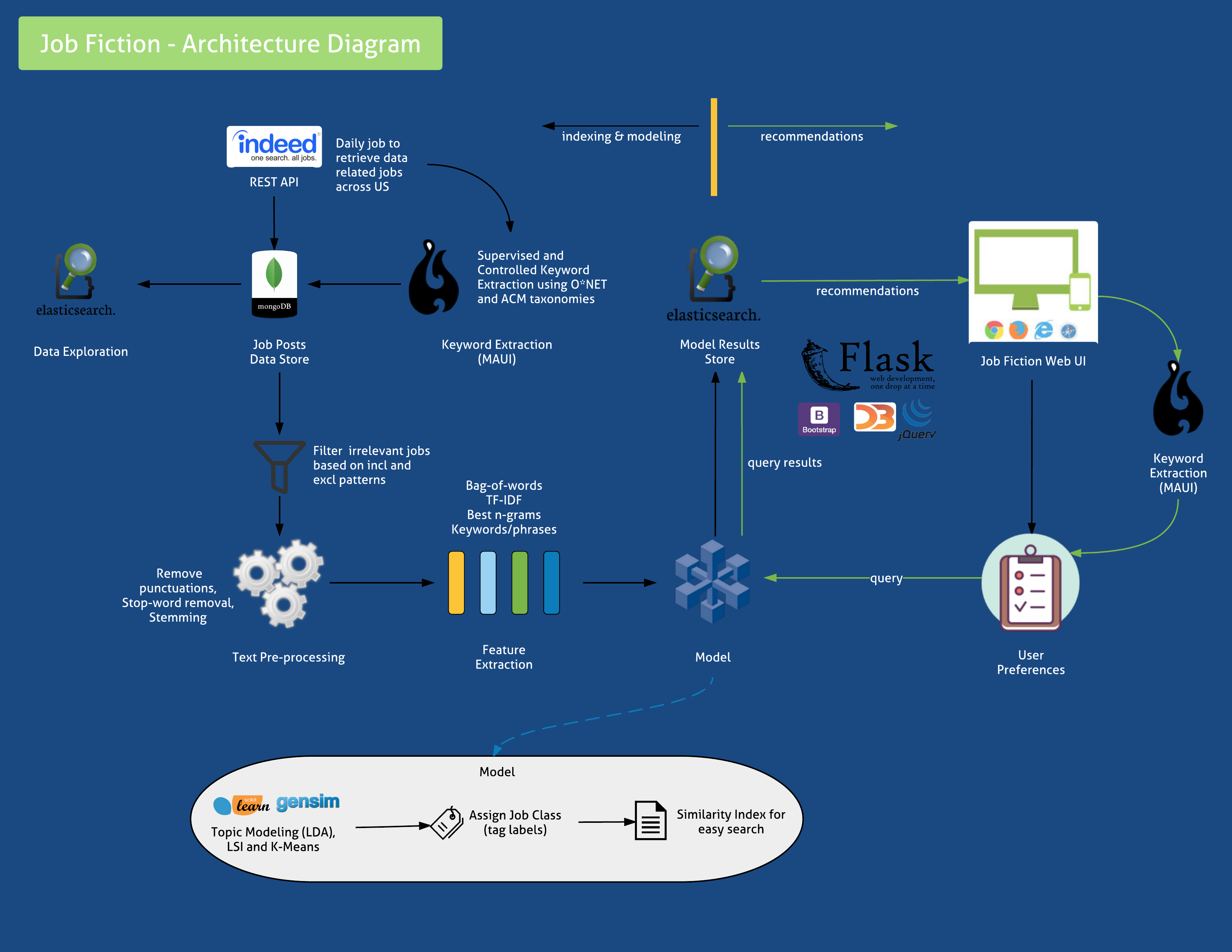
Application components and data pipeline
Tools and technologies to make the solution approach work
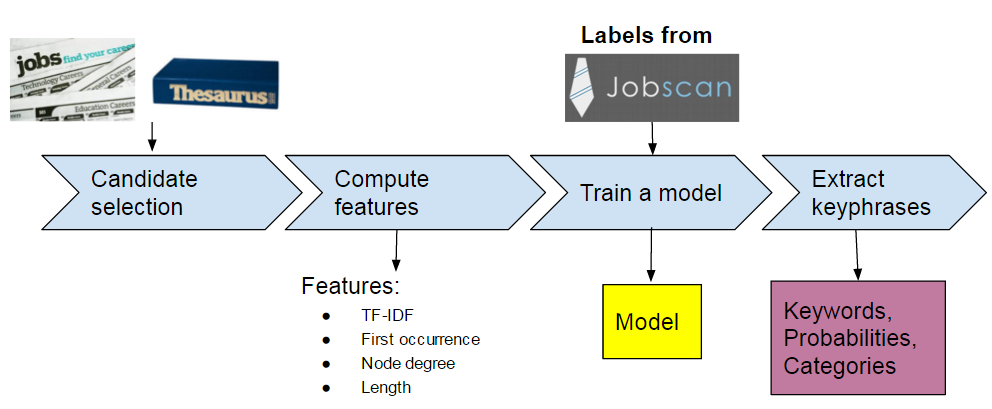
How key words and phrases are detected
Text normalization and filtering noise from data
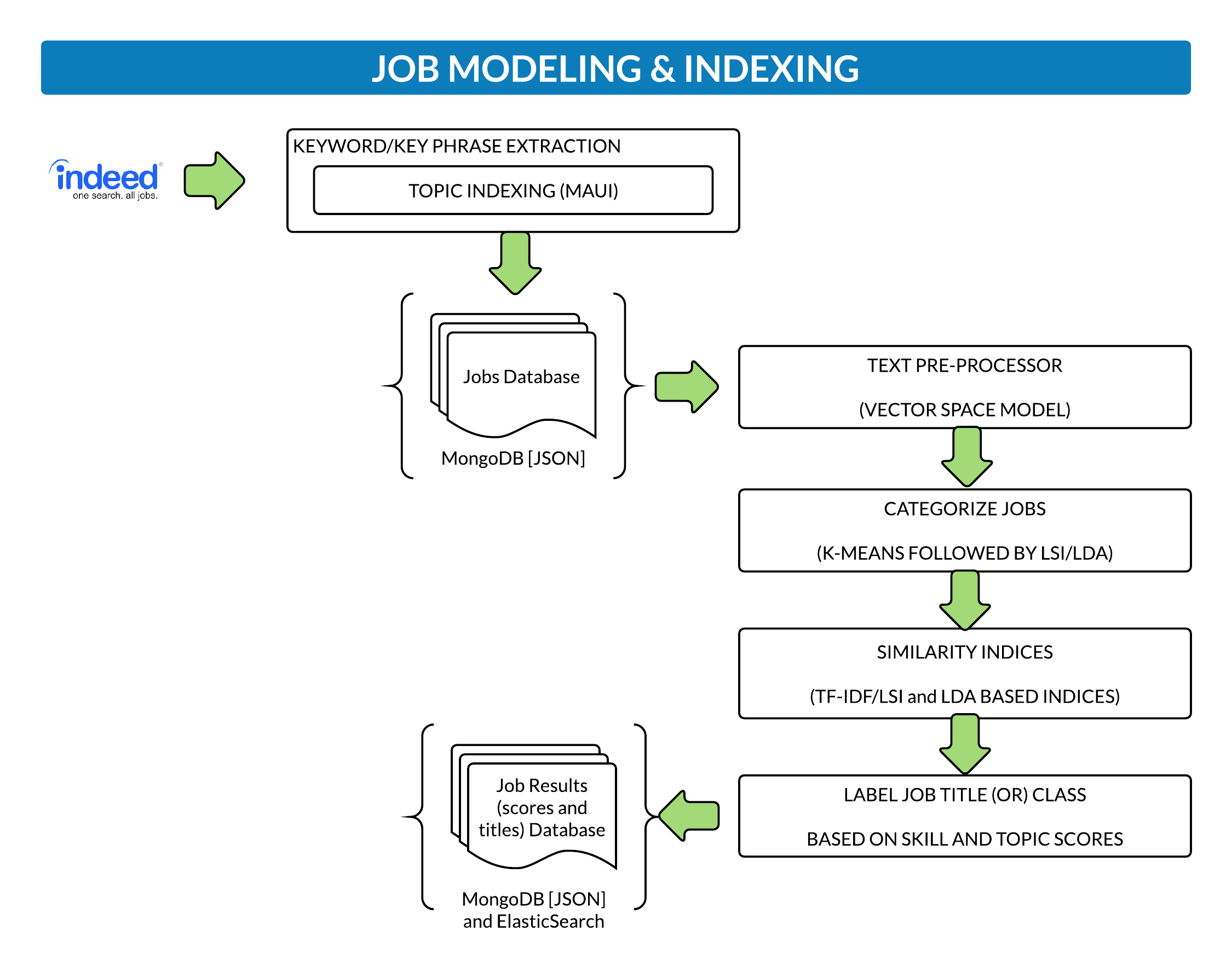
Topic modeling and indexing job posts
How recommendations work and job results are retrieved
How well the model works and does not work
What we learnt, what we could have changed and next steps
Public repo, view and fork the code
Play time!! Launch the app and give it a swirl

Get in touch
Get in touch with us if you would like to know more about the project or our team.

Angela Gunn

Rajesh Thallam
